Google Search Image Dataset으로 Pytorch, YOLOv5 이용한 Detection 모델 학습 시키기
Note :윤동글님의 안내겨 탐지 모델 게시물보고 참고
1) Google Search 결과로 나오는 10가지 야채들에 대해 데이터 셋 모으기
윤동글님 블로그의 Chrome Driver 이용하여 scrap하는 코드로 각각 Cabbage, Carrot, Garlic, Mushroom, Onion, Pepper, Potato, Spring_Onion, Tomato, Zucchini 10가지 야채에대해서 약 500개씩 이미지를 저장했다.
아래와 같은 파이썬 페키지 사용해서 코드가 짜여져있다.
import urllib.request #웹 url을 파이썬이 인식할 수 있게하는 패키지
from bs4 import BeautifulSoup #html에서 데이터 검색을 용이하게 하는 패키지
from selenium import webdriver # 웹 애플리케이션의 테스트를 자동화하기 위한 프레임 워크
from selenium.webdriver.common.keys import Keys #손으로 클릭하는것을 컴퓨터가 대신
전체 코드가 아닌 주요 부분만 보면, 아래와 같은 방법으로 브라우져를 세팅하고,
binary = '/Users/kanakim/chromedriver/chromedriver' #chromedriver 세팅
browser = webdriver.Chrome(binary) #브라우저를 인스터화
browser.get("https://www.google.co.kr/imghp?hl=ko&tab=ri&ogbl") #구글 이미지검색 base url
elem = browser.find_element_by_xpath("//*[@class='gLFyf gsfi']") #검색창에 해당하는 html찾고 elementary로 취한다.
elem.send_keys("애호박") #elmentary에 검색어 전달하고,
elem.submit() #submit
크롬 브라우저에서 이미지 검색결과 바디 부분을에서 현재 불러온 이미지 소스를 가져오고, 이미지가 있는 url를 이용해서 이미지를 각각 저장한다.
html = browser.page_source # 크롬브라우져에서 현재 불러온 소스 가져옴
soup = BeautifulSoup(html, "lxml") # html 코드를 검색할 수 있도록 설정
def fetch_list_url():
params = []
imgList = soup.find_all("img", class_="rg_i Q4LuWd") # 구글 이미지 url 이 있는 img 태그의 _img 클래스에 가서
for im in imgList:
try :
params.append(im["src"]) # params 리스트에 image url 을 담음
except KeyError:
params.append(im["data-src"])
return params
실행은 전체 python코드 안에서 검색어 부분과 이미지가 저장될 부분의 path만 수정하고 python program.py로 실행하면된다. 그러면 설저한 경로에 검색한 이미지들이 저장되게 된다.
저장된 이미지중에서 트레이닝에 쓸 수 없는 이미지는 삭제하면서 정리한다.
데이터를 모두 저장하고 난 다음에 images라는 폴더를 만들어서 저장한 이미지를 모두 모은다 이때 클래스 별로 저장되어있으면 나중에 labeling할때 편하니까 옮길때마다 번호로 이름 바꿔서 옮기는게 좋다.
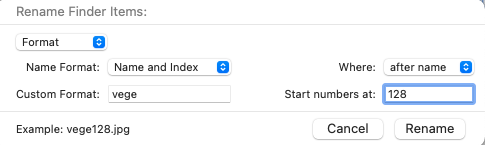
그 다음 opencv 이용해서 저장한 이미지들을 Resize해준다. 코드는 그냥 path에 있는 .jpg 확장자의 이미지들만 불러와서, 이미지의 크기를 416, 416 (혹은 640, 640)으로 조절하고, 조절한 이미지를 지정된 경로에 저장한다.
import cv2
import os
import glob
import numpy as np
from pathlib import Path
path =Path("/Users/kanakim/google_vegetables/zucchini/") #원본 사진이 있는 폴더 위치
path = path.glob("*.jpg")
count = 0
for k in path :
img = cv2.imread(str(k))
height = np.size(img, 0)
width = np.size(img, 1)
resize_img = cv2.resize(img, (416 , 416), interpolation=cv2.INTER_CUBIC) #사진크기
cv2.imwrite('/Users/kanakim/google_vegetables/zucchini_resize/' + str(count) + ".jpg", resize_img) #리사이즈된 후 사진이 저장될 폴더 위치
count += 1
2) Labeling using labelImg
tzutalin의 labeImg 프로그램 이용하여서 custom dataset에 대해 라벨링.
먼저 images폴더 위치한 자리에 같이 labels라는 폴더도 생성해준다. 그리고 이 안에다가 classes.txt라는 텍스트파일을 생성해서 labeling할 클래스들을 쭉 적는다.
macOS에 대해 설치하는 방법도 깃에 나와있다.
git clone https://github.com/tzutalin/labelImg.git
pip3 install pyqt5 lxml # Install qt and lxml by pip
cd labelImg
make qt5py3
python3 labelImg.py
설치를 하고나서 python3 labelImg.py로 실행시키면 Qt창이 뜨게 된다. 여기서 image가 저장된 폴더 불러오고, label저장할 폴더 설정하고 draw rect tool이용해서 labeling을 하면된다. 이때 프로그램이 갑자기 종료되거나 껐다 키게 되면 클래스들이 초기화되면서 인덱싱 문제가 발생하는데 이거를 1800개 이미지 다 라벨링 하고 나서 알아버렸다 ㅜ 그래서 코드 새로 짜서 클래스 다바꿔주느라 하루 다 날려먹었다.
그래서 알아낸게 일단 labelImg/data 안에서 predefubed_classes.txt라는 파일이 있는데 이 안의 클래스들을 사용할 클래스들로 바꿔주고 하는 것이 정신건강에 좋다.
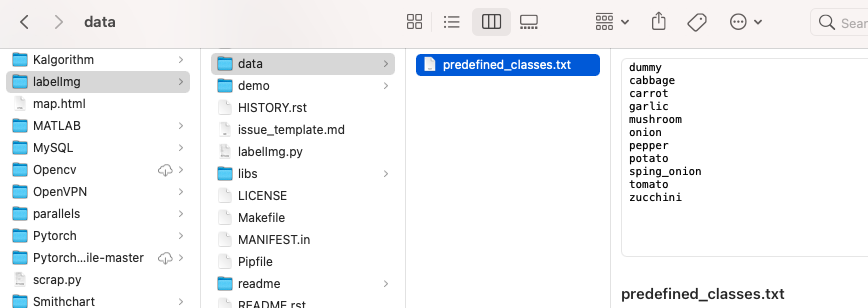
이걸 안바꾸게 되면, 라벨링 확인할려고 전에 이미지 클릭했는데 out of index 뜨면서 프로그램 강종되고, 라벨링된 텍스트 파일 확인하면 엉망진창이 된것을 볼 수있다. 그리고 인덱스가 꼬여있어서 클래스 수보다 더 높은 번호가 매겨져있다면 계속 train.py 딱 하는 마지막 부분에서 계속 에러가 나서 화가잔뜩 날수가있다.
그래서 클래스 이름 바꿔주는 코드 짜서 싸악 갈아엎었다 ㅠㅠ 일단 아래 코드로 클래스 수보다 많은 클래스 가지고 있는 파일들을 찾아낸다. ( 확인용 )
import glob
import os
from pathlib import Path
fpath = Path("/Users/kanakim/google_vegetables/export/labels/")
fpath = fpath.glob("*.txt")
for k in fpath :
fr = open(str(k), 'r')
lines = fr.readlines()
for line in lines :
x = line.split()[0]
ix = int(x)
if ix > 10 :
print(k, x)
fr.close()
그 다음에 해당 이미지에 보면서 어떤 값으로 바꿔야하는지 알아낸 다음에 코드에 넣어준다….. 이게 코드도 또 바보같이 짰더니 이틀동안 라벨링한게 다 날라가부렸다. 헤헤헿ㅎㅎ헿 근데 다행히 구글드라이브에 남아있어서 주어가지고 썼다.
for k in fpath :
fr = open(str(k), 'r')
lines = fr.readlines()
for line in lines :
if x == '16' :
fw = open(str(k), 'w')
fw.write(line.replace(x,'4'))
fw.close()
elif x == '19' :
fw = open(str(k), 'w')
fw.write(line.replace(x,'7'))
fw.close()
fr.close()
라벨링이 끝났으면 이제 Colab으로 넘어가서 Training을 시키면 된다.
그 전에 data.yaml ( google_vegetable.yaml ) 파일을 만들어서 yolov5 양식에 맞게 생성해준다.
train: ../train/images
val: ../valid/images
nc : 11
names: ['-', 'cabbage', 'carrot', 'garlic', 'mushroom', 'onion', 'pepper', 'potato', 'spring_onion', 'tomato', 'zucchini']
그 후, 구글드라이브에 images랑 labels 폴더, data.yaml파일이 있는 폴더를 업로드하고,
내 구글드라이브를 마운트해서 업로드한 데이터에 접근할 수 있게한다.

3) Yolov5 세팅
저번 트레이닝과 마찬가지로 yolov5를 clone하고 requirements.txt를 install한다.
%cd /content
!git clone https://github.com/ultralytics/yolov5.git
%cd /content/yolov5/
!pip install -r requirements.txt
/content
Cloning into 'yolov5'...
remote: Enumerating objects: 6290, done.[K
remote: Counting objects: 100% (85/85), done.[K
remote: Compressing objects: 100% (61/61), done.[K
remote: Total 6290 (delta 40), reused 59 (delta 24), pack-reused 6205[K
Receiving objects: 100% (6290/6290), 8.54 MiB | 39.03 MiB/s, done.
Resolving deltas: 100% (4294/4294), done.
/content/yolov5
Installing collected packages: PyYAML, thop
Found existing installation: PyYAML 3.13
Uninstalling PyYAML-3.13:
Successfully uninstalled PyYAML-3.13
Successfully installed PyYAML-5.4.1 thop-0.0.31.post2005241907
4) 데이터 나누기
드라이브에 마운트한 이미지들을 Training, Validation set으로 가각 나눈다. 이때 비율을 8:2로 설정하였다. image들이 어떻게 나뉘었는지 저장하기 위해 train, val 각각의 txt파일에 이미지들의 file명을 저장해준다.
%cd /
from glob import glob
img_list = glob('/content/drive/MyDrive/google_vegetables/export/images/*.jpg')
print(len(img_list))
from sklearn.model_selection import train_test_split
train_img_list, val_img_list = train_test_split(img_list, test_size=0.2, random_state=1215)
print(len(train_img_list), len(val_img_list))
with open('/content/drive/MyDrive/google_vegetables/train.txt', 'w') as f :
f.write('\n'.join(train_img_list)+'\n')
with open('/content/drive/MyDrive/google_vegetables/val.txt', 'w') as f :
f.write('\n'.join(val_img_list)+'\n')
/
1702
1361 341
yolov5 training에 사용될 yaml파일에 각각 train, val text 파일의 경로를 저장해준다.
import yaml
with open('/content/drive/MyDrive/google_vegetables/google_vegetables.yaml', 'r') as f:
data = yaml.load(f)
print(data)
data['train'] = '/content/drive/MyDrive/google_vegetables/train.txt'
data['val'] = '/content/drive/MyDrive/google_vegetables/val.txt'
with open('/content/drive/MyDrive/google_vegetables/google_vegetables.yaml', 'w') as f:
yaml.dump(data, f)
print(data)
{'names': ['dum', 'cabbage', 'carrot', 'garlic', 'mushroom', 'onion', 'pepper', 'potato', 'spring_onion', 'tomato', 'zucchini'], 'nc': 11, 'train': '/content/drive/MyDrive/google_vegetables/train.txt', 'val': '/content/drive/MyDrive/google_vegetables/val.txt'}
{'names': ['dum', 'cabbage', 'carrot', 'garlic', 'mushroom', 'onion', 'pepper', 'potato', 'spring_onion', 'tomato', 'zucchini'], 'nc': 11, 'train': '/content/drive/MyDrive/google_vegetables/train.txt', 'val': '/content/drive/MyDrive/google_vegetables/val.txt'}
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:3: YAMLLoadWarning: calling yaml.load() without Loader=... is deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.org/load for full details.
This is separate from the ipykernel package so we can avoid doing imports until
5) Training
모든 데이터가 준비되고, 학습과정을 중간에 확인할 수 있게 wandb를 세팅해준다.
%pip install -q wandb
import wandb
wandb.login()
[K |████████████████████████████████| 1.8MB 9.9MB/s
[K |████████████████████████████████| 133kB 52.5MB/s
[K |████████████████████████████████| 102kB 11.4MB/s
[K |████████████████████████████████| 174kB 54.8MB/s
[K |████████████████████████████████| 71kB 10.8MB/s
[?25h Building wheel for pathtools (setup.py) ... [?25l[?25hdone
Building wheel for subprocess32 (setup.py) ... [?25l[?25hdone
<IPython.core.display.Javascript object>
[34m[1mwandb[0m: Appending key for api.wandb.ai to your netrc file: /root/.netrc
True
yolov5의 train.py 코드를 이용해서 모델을 학습시킨다. 이때 yaml파일을 알려주고, pre trained 모델의 선택은 m size인 yolov5m.pt로 한다. 아무래도 데이터의 질이 좋지 않은 것 같아서 인식률을 높이기 위해서 저번보다 좀더 큰 사이즈를 선택했는데 맞는 선택일지 모르겠다. ㅎㅎ
지금은 학습중 !!! epoch 64에서 GPU 다 써가지고 멈춰버렸다 빡쳐서 바로 pro 결제해버리귀~
%cd /content/yolov5
!python train.py --img 416 --batch 16 --epochs 200 --data /content/drive/MyDrive/google_vegetables/google_vegetables.yaml --weights yolov5m.pt --name vegetables_yolov5 --nosave --cache
/content/yolov5
[34m[1mgithub: [0mup to date with https://github.com/ultralytics/yolov5 ✅
YOLOv5 🚀 v5.0-90-g06372b1 torch 1.8.1+cu101 CUDA:0 (Tesla P100-PCIE-16GB, 16280.875MB)
Namespace(adam=False, artifact_alias='latest', batch_size=16, bbox_interval=-1, bucket='', cache_images=True, cfg='', data='/content/drive/MyDrive/google_vegetables/google_vegetables.yaml', device='', entity=None, epochs=200, evolve=False, exist_ok=False, global_rank=-1, hyp='data/hyp.scratch.yaml', image_weights=False, img_size=[416, 416], label_smoothing=0.0, linear_lr=False, local_rank=-1, multi_scale=False, name='vegetables_yolov5', noautoanchor=False, nosave=True, notest=False, project='runs/train', quad=False, rect=False, resume=False, save_dir='runs/train/vegetables_yolov5', save_period=-1, single_cls=False, sync_bn=False, total_batch_size=16, upload_dataset=False, weights='yolov5m.pt', workers=8, world_size=1)
[34m[1mtensorboard: [0mStart with 'tensorboard --logdir runs/train', view at http://localhost:6006/
2021-05-14 05:49:31.264226: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
[34m[1mhyperparameters: [0mlr0=0.01, lrf=0.2, momentum=0.937, weight_decay=0.0005, warmup_epochs=3.0, warmup_momentum=0.8, warmup_bias_lr=0.1, box=0.05, cls=0.5, cls_pw=1.0, obj=1.0, obj_pw=1.0, iou_t=0.2, anchor_t=4.0, fl_gamma=0.0, hsv_h=0.015, hsv_s=0.7, hsv_v=0.4, degrees=0.0, translate=0.1, scale=0.5, shear=0.0, perspective=0.0, flipud=0.0, fliplr=0.5, mosaic=1.0, mixup=0.0
[34m[1mwandb[0m: Currently logged in as: [33mkka-na[0m (use `wandb login --relogin` to force relogin)
2021-05-14 05:49:33.340179: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.11.0
[34m[1mwandb[0m: Tracking run with wandb version 0.10.30
[34m[1mwandb[0m: Syncing run [33mvegetables_yolov5[0m
[34m[1mwandb[0m: ⭐️ View project at [34m[4mhttps://wandb.ai/kka-na/YOLOv5[0m
[34m[1mwandb[0m: 🚀 View run at [34m[4mhttps://wandb.ai/kka-na/YOLOv5/runs/2xcrm71i[0m
[34m[1mwandb[0m: Run data is saved locally in /content/yolov5/wandb/run-20210514_054932-2xcrm71i
[34m[1mwandb[0m: Run `wandb offline` to turn off syncing.
Downloading https://github.com/ultralytics/yolov5/releases/download/v5.0/yolov5m.pt to yolov5m.pt...
100%|██████████████████████████████████████| 41.1M/41.1M [00:01<00:00, 41.2MB/s]
Overriding model.yaml nc=80 with nc=11
from n params module arguments
0 -1 1 5280 models.common.Focus [3, 48, 3]
1 -1 1 41664 models.common.Conv [48, 96, 3, 2]
2 -1 1 65280 models.common.C3 [96, 96, 2]
3 -1 1 166272 models.common.Conv [96, 192, 3, 2]
4 -1 1 629760 models.common.C3 [192, 192, 6]
5 -1 1 664320 models.common.Conv [192, 384, 3, 2]
6 -1 1 2512896 models.common.C3 [384, 384, 6]
7 -1 1 2655744 models.common.Conv [384, 768, 3, 2]
8 -1 1 1476864 models.common.SPP [768, 768, [5, 9, 13]]
9 -1 1 4134912 models.common.C3 [768, 768, 2, False]
10 -1 1 295680 models.common.Conv [768, 384, 1, 1]
11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
12 [-1, 6] 1 0 models.common.Concat [1]
13 -1 1 1182720 models.common.C3 [768, 384, 2, False]
14 -1 1 74112 models.common.Conv [384, 192, 1, 1]
15 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
16 [-1, 4] 1 0 models.common.Concat [1]
17 -1 1 296448 models.common.C3 [384, 192, 2, False]
18 -1 1 332160 models.common.Conv [192, 192, 3, 2]
19 [-1, 14] 1 0 models.common.Concat [1]
20 -1 1 1035264 models.common.C3 [384, 384, 2, False]
21 -1 1 1327872 models.common.Conv [384, 384, 3, 2]
22 [-1, 10] 1 0 models.common.Concat [1]
23 -1 1 4134912 models.common.C3 [768, 768, 2, False]
24 [17, 20, 23] 1 64656 models.yolo.Detect [11, [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]], [192, 384, 768]]
Model Summary: 391 layers, 21096816 parameters, 21096816 gradients, 50.5 GFLOPS
Transferred 500/506 items from yolov5m.pt
Scaled weight_decay = 0.0005
Optimizer groups: 86 .bias, 86 conv.weight, 83 other
[34m[1mtrain: [0mScanning '/content/drive/MyDrive/google_vegetables/train.cache' images an[0m
[34m[1mtrain: [0mCaching images (0.7GB): 100%|████████| 1361/1361 [00:48<00:00, 28.05it/s][0m
[34m[1mval: [0mScanning '/content/drive/MyDrive/google_vegetables/val.cache' images and la[0m
[34m[1mval: [0mCaching images (0.2GB): 100%|████████████| 341/341 [00:12<00:00, 27.50it/s][0m
Plotting labels...
[34m[1mautoanchor: [0mAnalyzing anchors... anchors/target = 4.78, Best Possible Recall (BPR) = 0.9996
Image sizes 416 train, 416 test
Using 4 dataloader workers
Logging results to runs/train/vegetables_yolov5
Starting training for 200 epochs...
Epoch gpu_mem box obj cls total labels img_size
0/199 3.04G 0.09726 0.04756 0.0655 0.2103 78 416
from IPython.display import Image
import os
val_img_path = val_img_list[3]
!python detect.py --weights /content/yolov5/runs/train/vegetables_yolov5/weights/best.pt --img 416 --conf 0.5 --source "{val_img_path}"
Namespace(agnostic_nms=False, augment=False, classes=None, conf_thres=0.5, device='', exist_ok=False, hide_conf=False, hide_labels=False, img_size=416, iou_thres=0.45, line_thickness=3, name='exp', nosave=False, project='runs/detect', save_conf=False, save_crop=False, save_txt=False, source='/content/drive/MyDrive/google_vegetables/export/images/vegetable1498.jpg', update=False, view_img=False, weights=['/content/yolov5/runs/train/vegetables_yolov5/weights/best.pt'])
YOLOv5 🚀 v5.0-90-g06372b1 torch 1.8.1+cu101 CUDA:0 (Tesla T4, 15109.75MB)
Fusing layers...
Model Summary: 308 layers, 21078048 parameters, 0 gradients, 50.4 GFLOPS
image 1/1 /content/drive/MyDrive/google_vegetables/export/images/vegetable1498.jpg: 416x416 Done. (0.014s)
Results saved to runs/detect/exp
Done. (0.034s)